TrueNAS + ZFS is great! Ok but basically why is it great?
And well, among other things, because it has built-in ZFS support on board because ZFS itself is somehow not super user frendy. and ZFS is super! Ok but why is ZFS super? And that's what I'm going to talk about today. First there will be a little introduction. There will also be about those whole pools, ARCs, L2ARCs, SLOGs and ZILs. I'll talk about how ZFS has structured data storage and why it's so cool and then I'll cover in the lab how we can make it even much faster.
ZFS
At the outset, let the obvious fall out. ZFS or Zettabyte File System.
And specifically, TrueNAS uses OpenZFS, which is an open source version of ZFS, which as ZFS is closed and developed before Oracle. For the sake of clarification when I say ZFS I will refer to OpenZFS. Good good and what is this Zettabyte? Current and especially older file systems have their limitations. For example, even Windows 10 if it is 32-bit and not 64-bit version will not be able to handle a disk larger than 2TB. For example, let's take a disk size of 1TB is now say the standard. So 1000 such 1TB drives are 1PB (PetaByte). 1000 PB is 1 EB (ExaByte). 1,000 EBs are 1 ZB (ZettaByte). So 1 ZettaByte is 1000 x 1000 x 1000 x 1TB disk. A lot right?
Well, it's good only that this ZettaByte is all that's left in the name. In fact, now the theoretical capacity of one zpoll in ZFS is 256 quadrillion ZettaBytes, .... seriously, until I had to look up what that quadrillion is. Remember those 1TB drives of ours? So the theoretical capacity of one zpoll is 1,000,000,000,000,000,000 such drives !!! Sorry couldn't resist a bit of calculation.
ZFS has quite a few advantages over regular file systems. You could say that it is such a meta file system. A way of organizing the data on which file systems are based.
ZFS auto-healing
ZFS is distinguished, for example, by its auto-healing function. Whenever data is read from a disk, it is always checked for correctness with checksums, and even if for some reason the data read was not correct, the correct value is calculated on the fly, the incorrect one is overwritten on the disks and the user gets the correct data. This significantly differentiates ZFS from ordinary RAID which may even be "unaware" that they are giving the wrong data. You can also manually force a consistency check of the entire zPoll-a feature on ZFS called scrub.
Moving on to how data storage is organized in ZFS.
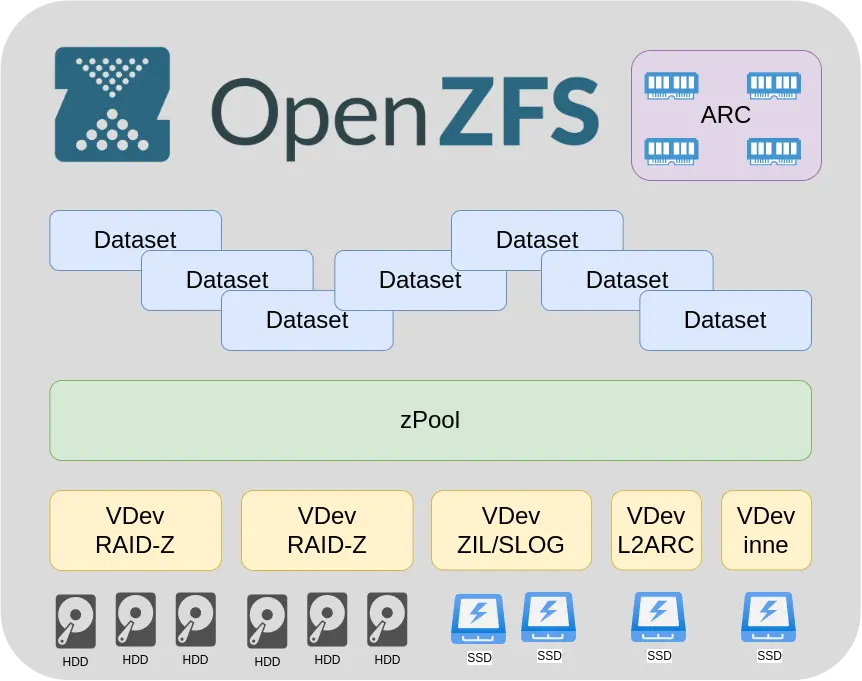
VDev
Groups of disks form Vdevs (Virtual Device) they are presented to ZFS as a single device. Disks in a VDev depending on function and need can be assigned as individual disks if redundancy is not needed, such as L2ARC but more on that later, as mirrored disks if needed, or as RAID-Z which is basically the essence of our ZFS.
RAID-Z
Depending on the need for data protection and the number of drives, we can configure in version Z1 Z2 Z3. Version numbers indicate the number of redundant disks. Which gives the resistance to failure of one two or three drives in each VDev. That is, if the VDev is in RAID-Z3 it means that we need a minimum of 4 disks. In simple terms, we can say one for data and three for redundancy. For RAID-Z2 a minimum of three disks. For RAID-Z1 a minimum of two drives, Of course, this is a suboptimal example, but the point is the principle. RAID-Z rebuild time after disk replacement is an important thing, especially for large installations. Here, too, ZFS strongly advises because the time depends on the amount of data stored in the array. ZFS "knows" when it has how much and where it has data, so when rebuilding it only moves the actually used space. Unlike the classic RAID1 or RAID5, where rebuilding a RAID basically means putting a WHOLE new disk bit by bit.
| Minimum number of drives | Resistance to disk failure (N-number of disks) | Approximate array capacity for 1TB drives (C-disk capacity) | Approximate array capacity for N disks with C capacity | |
| RAID-Z1 | 2 | 1 | 1TB | (N-1)xC |
| RAID-Z2 | 3 | 2 | 1TB | (N-2)xC |
| RAID-Z3 | 4 | 3 | 1TB | (N-3)xC |
zPool
It is our file system to which we can, if necessary n.e.g. add new VDevs if we run out of space. Even on the fly without a reboot. I know that there has been work on subtracting Vdevs to reduce our zPoll, but the functionality as far as I know has not been implemented. I would like to make it clear, you can easily expand our zPoll by adding a new Vdev but not expanding the Vdev itself. Currently, there is no production capability to expand the Vdev with RAID-Z. I know that work among the developers of ZFS itself was in progress, but as far as I know currently i.e. as of august 2022 in TrueNAS CORE 13-1U there is no such possibility. In practice, as a form of workaround, you can move the data to another location rebuild the Vdev with more disks. Not very convenient but sometimes necessary. You can also add and subtract to zPoll on the fly, for example, Vdevs that buffer reads and writes, i.e. L2ARC and SLOG/ZIL
ARC (Adaptive Replacement Cache)
This is a huge advantage of ZFS. ARC is a cache that holds the most frequently read data, and it uses the fastest memory possible - RAM. RAM is many times faster than any SSD or even more classic disk drives. This makes the most frequently used data available in practice without any delays caused by the mere access and reading of data from the disk. It is said that ZFS is memory-intensive - well... yes and no - it will use as much RAM as it can in favor of the ARC cache. In practice, this means that how much RAM we would have after some time of use it will be all taken up. But is that a bad thing? It means that the data we use most often has gathered there and we have super-fast access to it, which is the point, right? Let's also remember that it is an adaptive memory, so the occupied space will be reduced if it is needed and, for example, we run some service or the system itself will need this RAM. ARC reduction will come at the expense, of course, of the amount of data cached in ARC. So ZFS is not so much memory-intensive, but tries to maximize the use of available resources as cache. But the second conclusion is that, in practice, the more RAM, the easier our TrueNAS server will handle in the case of mass reads that are repeated. In practice, we say about 1GB RAM for every 1TB of disk array capacity, but no less than 8GB RAM. However, I would recommend a minimum of 16GB RAM. Or more? It depends on your needs and resources, of course. As an example, let's have a virtual server or jail or docker instance running on our TrueNAS with a database. In practice, we gain something like a database in RAM - huge read speedup - Cool right?
Vdev – L2ARC (Layer 2 Adaptive Replacement Cache)
This is the second level of the read buffer after ARC. It is optional. The principle of operation is that the most frequently used data which, however, no longer fit and ARC will be moved is L2ARC. If performance is the most important thing for us, however, we should invest in more RAM, but if we have an array composed of disk drives, which is not at all uncommon in high-capacity arrays, such L2ARC in the form of a single NVMe drive can in some cases significantly improve read performance. Note that there is no need for any redundancy here. There is no unique data on the disk. The buffer is rebuilt according to current needs always after a reboot. We can even add or remove it "on the fly" without any reboots.
Vdev – SLOG (Separate intent log)/ZIL (ZFS intent log)
This is where the adventure of writing data with ZFS begins. SLOG is simplifying the data storage buffer but for quite specific cases. To explain and understand when it's worth it, we need to deviate a bit. There are two types of write operations, synchronous and asynchronous. The difference is that in synchronous, the writer wishes to get a confirmation that the data has been successfully written. In the case of asynchronous writes, the data is accumulated in a buffer, aggregated and written to disk in ordered sequences, which greatly optimizes write performance. If the writer wishes to write synchronously, write performance, especially for small random data, drops dramatically. In addition, in the case of asynchronous writing u there is a problem under the title: what if we lose power? The data was accepted by the server, but because it was in RAM it is gone.
As a solution to the problem of data loss in asynchronous mode comes the inclusion of synchronous mode which brings us performance problems, so as a solution to the performance problem of small random writes comes SLOG. Especially in the case if our array is made of disk drives, then using NVMe disk as SLOG will significantly increase performance for small random writes. The size of such a disk really does not need to be large because it is only a buffer which is emptied after writing to the target disks. Realistically in the vast majority of situations it will be difficult to fill even a 16GB disk, yes I was not mistaken 16GB and there are such. Remember that unlike read buffers in this case we are dealing with data that is nowhere to be found. It is recommended that SLOGs be used in mirrored configurations in case one drive fails.
Dataset
Only here, within our zPoll, we can create virtual resources in which we will keep our data. We make such Datasets available as, for example, a Samba file server, Nexcloud file space, or other. For each Dataset, we can specify the size, encryption, compression, access rights, deduplication capability and several others.
Copy on Write
This is another very interesting feature of ZFS. It relies on the fact that if you want to modify only one piece in a block of data, the entire block of data is rewritten to a new location in a modified form. As soon as the data is successfully written, the "address" where the data is written is changed. It greatly increases the resistance to problems related to unforeseen failures during writing because we do not touch the old data. In the traditional way of writing, if a failure occurs while writing the swapped part of the data, we have neither old nor new data. With copy-on-write we have the old data all the time.
Other interesting ZFS features
- built-in compression of data written to disk
- disk data encryption
- easy disk replacement , I made a material about it .
- snapshots - more than once they save you from a problem I also made material about it .
- raplication of data to another server - about it .
- deduplication - very useful if we more or less consciously keep the same data many times. In the process of deduplication such data will be detected and kept only as a link to the original without taking up additional space.
ZFS optimization
It is complex and depends on the specific case, the type of data stored, hardware and others. In the material I only touch very roughly on the topic of optimization. Every installation is different and can create different loads. What I mean here is that sometimes, for example, when hosting large video files, the main parameter will be reading or writing a large amount of data, in practice throughput. Sometimes the most important will be fast access to random data as in the case of databases or parallel access by multiple users. Sometimes fast reading and sometimes fast writing will be important. In summary, ZFS optimization is very much dependent on the specific environment.
Środowisko testowe
RAIDy sprzętowe są bardzo dobrą sprawą i standardem w komputerach klasy serwerowej. W zdecydowanej większości wypadków to dobre rozwiązanie. Tylko, że .. nie w wypadku TrueNAS. Najlepiej jeżeli ZFS ma bezpośredni dostęp do dysków. Dlaczego? Ponieważ sprzętowy RAID „udaje” dysk i często posiada własne bufory. ZFS nie wie czy dane zostały skutecznie zapisane czy nie. Nie wie czy wszystkie dyski są sprawne czy nie. Dodatkowo dochodzi nam następny element do regularnej kontroli, czy dyski w RAID sprzętowym są ok. Słowem dublują się nam funkcję, komplikuje obsługa i zrozumienie co się dzieje a nie mamy w zasadzie wiele korzyści. Dlatego wskazaniem do serwera TrueNAS jest brak RAID sprzętowego.
I ran the tests directly on a machine running TrueNAS to avoid impacts related to latency or network bandwidth, for example.
Benchmark – fio
It is said that there are small lies, big lies and benchmarks, but somehow this had to be approached to have something to refer to. For testing, I use the "fio" program built into TrueNAS and other Linux-like creations.
Test commands
Disk recording
fio –name TEST –eta-newline=5s –filename=/mnt/test-pool/vdev-test/out-20GB2.bin –rw=write –size=20g –blocksize=64k –runtime=60 –numjobs=4 –group_reporting
- eta-newline - every how many times it should output a new line
- filename - location of the test file
- rw - type of operation
- size- amount of data
- blocksize - size of test blocks
- runtime - test time
- numjobs - number of parallel operations
Information on disk disposal
zpool iostat -v test-pool 1
- v - name of zPolla
- 1 - data refresh rate
I invite you to watch the video