TrueNAS + ZFS jest super! Ok ale w zasadzie czemu jest super?
A no między innymi dlatego, że na pokładzie ma wbudowaną obsługę ZFS bo sam ZFS jako taki nie jest jakoś super user frendy. a ZFS jest super! Ok ale dlaczego ZFS jest super? A o tym właśnie dzisiaj opowiem. Najpierw będzie małe wprowadzenie. Będzie też o tych całych pool-ach, ARC-ach, L2ARC-ach, SLOG-ach i ZIL-ach. Opowiem jak ZFS ma zorganizowane przechowywanie danych i dlaczego jest tak fajny a potem pokarzę w laboratorium jak jak możemy to jeszcze znacznie przyspieszyć.
ZFS
Na wstępnie niech z padnie oczywiste. ZFS czyli Zettabyte File System.
A konkretnie w TrueNAS użyto OpenZFS czyli otwarto źródłową wersję ZFS, który jako ZFS jest zamknięty i rozwijany przed Oracle. Dla uściślenia mówiąc ZFS będę mówił o OpenZFS. Dobra dobra a co to ten Zettabyte? Obecne a zwłaszcza starsze systemy plików mają swoje ograniczenia. np. nawet Windows 10 jeżeli jest w wersji 32-bit a nie 64-bit to nie będzie potrafił się obsłużyć dysku większego niż 2TB. Dla przykładu weźmy dysk wielkości 1TB to obecnie powiedzmy standard. Więc 1000 takich 1TB dysków to 1PB (PetaByte). 1000 PB to 1 EB (ExaByte). 1000 EB to 1 ZB (ZettaByte). Czyli 1 ZettaByte to 1000 x 1000 x 1000 x 1TB dysk. Dużo prawda?
No dobrze tylko, że ten ZettaByte to już tylko w nazwie pozostał. W zasadzie teraz teoretyczna pojemność jednego zpoll-a w ZFS to 256 quadrillion ZettaBytes, .. serio, aż musiałem sprawdzić co to jest ten quadrillion. Pamiętacie te nasze 1TB dyski? Więc pojemność teoretyczna jednego zpoll-a to 1 000 000 000 000 000 takich dysków !!! Przepraszam nie moglem się powstrzymać od odrobiny wyliczeń.
ZFS ma sporo zalet w porównaniu ze zwykłymi systemami plików. Można by powiedzieć, że jest taki meta systemem plików. Sposobem organizacji danych na których oparte są systemy plików.
ZFS auto-healing
ZFS wyróżnia na przykład funkcja auto-healing. Zawsze podczas odczytu danych z dysku sprawdza się ich poprawność z sumami kontrolnymi i nawet jeżeli z jakiegoś powodu odczytane dane nie były prawidłowe to w locie jest wyliczana prawidłowa wartość, nadpisywana ta niewłaściwa na dyskach a użytkownik dostaje właściwe dane. To znacząco odróżnia ZFS od zwykłych RAID które nawet mogą by „nieświadome” że podają złe dane. Można też ręcznie wymusić sprawdzenie spójności całego zPoll-a to funkcja na ZFS nazywa się scrub.
Przechodząc do tego jak zorganizowane jest przechowywanie danych w ZFS.
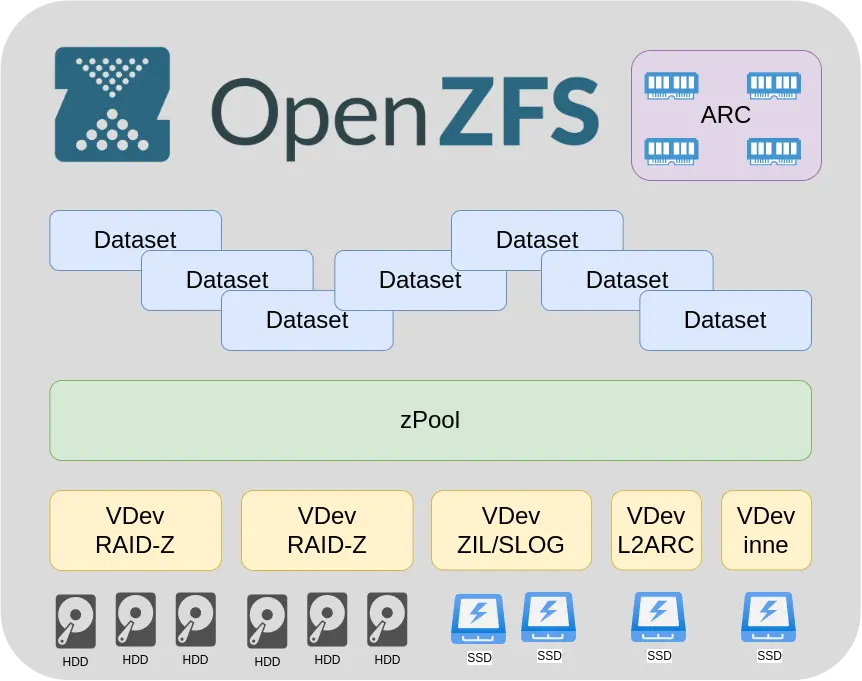
VDev
Grupy dysków tworzą Vdev-y (Virtual Device) są one przedstawiane do ZFS jako jedno urządzenie. Dyski w VDev zależnie od funkcji i potrzeby mogę być przypisane jako pojedyncze dyski, jeżeli nie ma potrzeby redundancji, na przykład L2ARC ale o tym później, jako dyski lustrzane jeżeli to potrzebne, lub jako RAID-Z co w zasadzie stanowi kwintesencję naszego ZFS.
RAID-Z
W zależności od potrzeby ochrony danych i ilości dysków możemy skonfigurować w wersji Z1 Z2 Z3. Numery wersji oznaczają ilość nadmiarowych dysków. Co daje odporność na awarię jednego dwóch lub trzech dysków w poszczególnych VDev. Czyli jeżeli VDev jest w RAID-Z3 to oznacza, że potrzebujemy minimum 4 dyski. W uproszczeniu można powiedzieć, że jeden na dane i trzy na nadmiarowość. Do RAID-Z2 minimum 3 dyski. Do RAID-Z1 minimum dwa dyski, Oczywiście to mało optymalny przykład ale chodzi o zasadę. Czas odbudowy RAID-Z po wymianie dysku jest ważną rzeczą zwłaszcza w wypadku dużych instalacji. Tu też ZFS mocno daje radę bo czas jest zależny ilości danych zapisanych w macierzy. ZFS „wie” kiedy ile i gdzie ma dane więc przy odbudowie przenosi tylko rzeczywiście wykorzystane miejsce. W odróżnieniu od klasycznych RAID1 czy RAID5 gdzie odbudowa RAID oznacza w zasadzie nałożenie CAŁEGO nowego dysku bit po bitcie.
| Minimalna ilość dysków | Odporność na awarię dysków (N-ilość dysków) | Przybliżona pojemność macierzy dla dysków 1TB (C-pojemność dysku) | Przybliżona pojemność macierzy dla N-dysków o C-pojemności | |
| RAID-Z1 | 2 | 1 | 1TB | (N-1)xC |
| RAID-Z2 | 3 | 2 | 1TB | (N-2)xC |
| RAID-Z3 | 4 | 3 | 1TB | (N-3)xC |
zPool
Jest naszym systemem plików do którego możemy w razie potrzeby n.p. dodawać nowe VDev-y jeżeli skończy się nam miejsce. Nawet w locie bez restartu. Wiem, że były prowadzone prace nad odejmowaniem Vdev-ów żeby zmniejszyć naszego zPoll-a ale funkcjonalność z tego co wiem nie została wdrożona. Chciał bym żeby to wybrzmiało jasno, można bez problemu rozszerzyć nasz zPoll przez dodanie nowego Vdev-a ale nie powiększenie samego Vdev-a. Obecnie nie ma produkcyjnej możliwości rozszerzenia Vdev-a z RAID-Z. Wiem, że prace wśród deweloperów samego ZFS trwały ale o ile wiem aktualnie czyli na sieprień 2022 w TrueNAS CORE 13-1U nie ma takiej możliwości. W praktyce jako formę obejścia można przenieść dane w inne miejsce przebudować Vdev-a z większą ilością dysków. Mało to wygodne ale czasem konieczne. Do zPoll-a można też w locie dodawać i odejmować na przykład Vdev-y buforujące zapis i odczyt czyli L2ARC i SLOG/ZIL
ARC (Adaptive Replacement Cache)
To olbrzymia zaleta ZFS. ARC to cache w którym trzymane są najczęściej odczytywane dane a używana jest to tego najszybsza możliwa do wykorzystania pamięci czyli RAM. Pamięć RAM jest wielokrotnie szybsza niż jakiekolwiek dyski SSD czy tym bardziej klasyczne talerzowe. Sprawia to, że dane najczęściej używane dostępne są w praktyce bez żadnych opóźnień spowodowanych samym dostępem i odczytam danych z dysku. Mówi się, że ZFS jest pamięciożerny – cóż.. tak i nie – użyje tyle RAM ile tylko będzie mógł na rzecz cache ARC. W praktyce oznacza to, że ile byśmy tego RAM nie mieli po jakimś czasie użytkowania będzie on cały zajęty. Ale czy to źle? Oznacza to, że zebrały się tam dane które używamy najczęściej i mamy do nich super szybki dostęp, a przecież o to na chodzi prawda? Pamiętajmy również tym, że jest to pamięć adaptacyjna, więc będzie redukowane zajęte miejsce jeżeli będzie potrzebne i na przykład odpalimy jakąś usługę czy sam system będzie tego RAM-u potrzebował. Redukcja ARC odbędzie się kosztem oczywiście ilości danych buforowanych w ARC. ZFS jest więc nie tyle pamięciożerny lecz stara się maksymalnie wykorzystać dostępne zasoby jako cache. Ale drugim wnioskiem jest to, że w praktyce im więcej RAM tym łatwiej nasz serwer TrueNAS będzie sobie radził w wypadku masowych odczytów które się powtarzają. W praktyce mówi się ok 1GB RAM na każdy 1TB pojemności macierzy dyskowej, jednak nie mniej nić 8GB RAM. Zalecał bym jednak minimum 16GB RAM. Czy więcej? To zależy od potrzeb i oczywiście zasobów. Takim przykładem niech będzie Virtualny serwer czy jail czy instancja dockera uruchomiony na naszym TrueNAS z bazą danych. W praktyce zyskujemy coś w rodzaju bazy danych w RAM – olbrzymie przyspieszenie odczytu – Fajne prawda?
Vdev – L2ARC (Layer 2 Adaptive Replacement Cache)
To drugi poziom bufora odczytu po ARC. Jest opcjonalny. Zasada działania jest taka, że najczęściej używane dane które jednak już nie mieszczą się a ARC będą przesuwane to L2ARC. Jeżeli najważniejszy jest dla nas wydajność to jednak powinniśmy zainwestować w większą ilość RAM ale jeżeli mamy macierz złożoną z dysków talerzowych, co nie jest wcale rzadkością w macierzach o dużej pojemności, to taki L2ARC w postaci jednego dysku NVMe może w niektórych wypadkach znacznie poprawić wydajność odczytu. Zwróćmy uwagę, że nie ma tu potrzeby żadnej redundancji. Na dysku nie ma żadnych niepowtarzalnych danych. Bufor jest odbudowywany według aktualnych potrzeb zawsze po restarcie. Możemy go nawet dodać lub usunąć „w locie” bez żadnych restartów.
Vdev – SLOG (Separate intent log)/ZIL (ZFS intent log)
Tutaj zaczyna się przygoda z zapisem danych z ZFS. SLOG to upraszczając bufor zapisu danych ale dla dosyć specyficznych przypadków. Żeby wytłumaczyć i zrozumieć kiedy warto to musimy trochę zboczyć z kursu. Są dwa rodzaje operacji zapisu, synchroniczne i asynchroniczne. Różnica jest taka, że w synchronicznych zapisujący życzy sobie dostać potwierdzenie, że dane zostały z sukcesem zapisane. W wypadku zapisu asynchronicznego dane są gromadzone w buforze, agregowane i zapisywane na dysk uporządkowanymi sekwencjami, co bardzo optymalizuje wydajność zapisu. Jeżeli zapisujący życzy sobie zapisu synchronicznego to wydajność zapisu, zwłaszcza małych losowych danych, spada dramatycznie. Ponadto w wypadku zapisu asynchronicznego u pojawia się kłopot pod tytułem: a co jeżeli utracimy zasilanie? Dane zostały przyjęte przez serwer ale ponieważ były w RAM to już ich nie ma.
Jako rozwiązanie problemu utraty danych w trybie asynchronicznym przychodzi włączenie trybu synchronicznego który przynosi nam problemy z wydajnością, więc jako rozwiązanie problemu wydajności przypadkowych małych zapisów przychodzi właśnie SLOG. Zwłaszcza w wypadku jeżeli nasza macierz jest z dysków talerzowych to wykorzystanie dysku NVMe jako SLOG znacząco podniesie wydajność dla drobnych przypadkowych zapisów. Wielkość takiego dysku naprawdę nie musi być duża ponieważ to tylko bufor który jest opróżniany po zapisie na docelowe dyski. Realnie w zdecydowanej większości sytuacji ciężko będzie zapełnić nawet 16GB dysk, tak nie pomyliłem się 16GB i są takie. Pamiętajcie, że w przeciwieństwie do buforów odczytu w tym wypadku mamy do czynienia z danymi których nigdzie indziej nie ma. Zalecane jest by SLOG-i były stosowane w konfiguracjach lustrzanych na wypadek awarii jednego dysku.
Dataset
Dopiero tutaj w ramach naszego zPoll-a możemy tworzyć wirtualne zasoby w których będziemy trzymać nasze dane. Takie Dataset-y udostępniamy jako na przykład jako serwer plików Samba, miejsce na pliki Nexcloud, czy inne. Dla każdego z Dataset-ów możemy określić wielkość, szyfrowanie, kompresję, prawa dostępu, możliwość deduplikacji i kilka innych.
Copy on Write
to następna bardzo ciekawa funkcja ZFS. Polega ona na tym, że jeżeli chcemy zmodyfikować tylko jeden kawałek w bloku danych to jest przepisywany cały blok danych w nowe miejsce w zmienionej formie. Jak dane zostanę skutecznie zapisane to zmienia się „adres” gdzie zapisane są dane. Bardzo podwyższa do odporność na problemy związane z nieprzewidzianymi awariami podczas zapisu ponieważ nie dotykamy starych danych. W tradycyjnym sposobie zapisu jeżeli wystąpi awaria podczas zapisu zamienionej części danych to nie mamy ani starych ani nowych danych. Przy zastosowaniu copy-on-write cały czas mamy stare dane.
Inne ciekawe funkcje ZFS
– wbudowana kompresja danych zapisywanych na dysku
– szyfrowanie danych na dysku
– łatwa wymiana dysku , zrobiłem o tym materiał <TU>
– snapschoty – nie raz ratują przed problemem o tym też zrobiłem materiał <TU>
– raplikacja danych na inny serwer – o tym <TU>
– deduplikacja – bardzo się przydaje jeżeli mniej lub bardziej świadomie trzymamy wiele razy te same dane. W procesie deduplacji takie dane będą wykryte i utrzymywane tylko jako link do oryginały nie zajmując dodatkowego miejsca.
Optymalizacja ZFS
Jest złożona i zależna od konkretnego przypadku, rodzaju przechowywanych danych, sprzętu i innych. W materiale poruszam tylko bardzo zgrubnie temat optymalizacji. Każda instalacja jest inna i może tworzyć inne obciążenia. Mam tu na myśli fakt, że czasem na przykład przy hostowaniu dużych plików video głównym parametrem będzie odczyt czy zapis dużej ilości danych, w praktyce przepustowość. Czasem najważniejsze będzie szybki dostęp do losowych danych jak w wypadku baz danych lub równoległy dostęp wielu użytkowników. Czasem istotny będzie szybki odczyt a czasem szybki zapis. Podsumowując optymalizacja ZFS jest bardzo ale to bardzo zależna od konkretnego środowiska.
Środowisko testowe
RAIDy sprzętowe są bardzo dobrą sprawą i standardem w komputerach klasy serwerowej. W zdecydowanej większości wypadków to dobre rozwiązanie. Tylko, że .. nie w wypadku TrueNAS. Najlepiej jeżeli ZFS ma bezpośredni dostęp do dysków. Dlaczego? Ponieważ sprzętowy RAID „udaje” dysk i często posiada własne bufory. ZFS nie wie czy dane zostały skutecznie zapisane czy nie. Nie wie czy wszystkie dyski są sprawne czy nie. Dodatkowo dochodzi nam następny element do regularnej kontroli, czy dyski w RAID sprzętowym są ok. Słowem dublują się nam funkcję, komplikuje obsługa i zrozumienie co się dzieje a nie mamy w zasadzie wiele korzyści. Dlatego wskazaniem do serwera TrueNAS jest brak RAID sprzętowego.
Testy przeprowadziłem bezpośrednio na maszynie z TrueNAS, żeby uniknąć wpływów związanych na przykład z opóźnieniami lub przepustowością sieć.
Benchmark – fio
Mówi się, że są małe kłamstwa, duże kłamstwa i benchmarki ale jakoś do tego trzeba było podejść żeby mieć do czego się odnieść. Do testów używam programu „fio” wbudowanego w TrueNAS i inne linuxopodobne twory.
Komendy testowe
Zapis na dysku
fio –name TEST –eta-newline=5s –filename=/mnt/test-pool/vdev-test/out-20GB2.bin –rw=write –size=20g –blocksize=64k –runtime=60 –numjobs=4 –group_reporting
– eta-newline – co ile ma wypisywać nową linię
– filename – położenie pliku testowego
– rw – rodzaj operacji
– size- ilość danych
– blocksize – wielkość bloków testowych
– runtime – czas testu
– numjobs – ilość równoległych operacji
Informacje o utylizacji dysków
zpool iostat -v test-pool 1
– v – nazwa zPolla
– 1 – szybkość odświeżania danych
Zapraszam do oglądania