W jakiejś części przypadków rozmowa o serwerach plików zaczyna się i kończy na tym jaka mają pojemność. I to jest też ok ale w tym materiale chciałem zagłębić się daleko poza wyliczenie pojemności w stronę skokowego wręcz skoku wydajności.
No dobrze ale skoro nie tylko pojemność to co jeszcze konkretnie będziemy mierzyć? I tutaj musimy trochę odpłynąć w bok bo nie ma czegoś takiego jak obiektywnie bezwzględna wydajność storage. Co więcej często dobre parametry dla jednego zastosowania sprawiają, że dla innego zastosowania parametry się pogarszają. Warto też przytoczyć starą prawdę o testach wydajności, że mamy trzy poziomy prawdy. Najpierw mamy prawdę potem kłamstwo a na końcu testy wydajności. Nie oznacza to oczywiście, że są bezużyteczne oznacza to tylko, że trzeba bardzo uważnie patrząc na wyniki testów bo często są przeprowadzane w rożnych warunkach, na innych danych, czy na innych urządzeniach. Chciałbym, żebyście brali wartości podane w tym materiale bardziej jako odniesienie do rzeczywistych zakresów niż konkretne wartości. Różnice mogą być znaczne a w tym materiale chciałbym się skupić wyłącznie na tym jaki wpływ na osiągi ma sposób konfiguracji dysków w poolu. Ale po kolei.
Parametry storage – przepustowość
Pierwszym z parametrów określających wydajność storage jest przepustowość. Jest to sekwencyjny zapis ciągłego strumienia danych. To ważny parametr przy przetwarzaniu kopii bezpieczeństwa lub przetwarzaniu dużych plików video. Pamiętajmy, że określone parametry osiągniemy tylko przy wyłącznym dostępie do dysku. Jeśli z danego dysku korzysta równolegle inny proces lub zaczniemy zapisywać dużą ilość małych plików wówczas osiągi spadają dramatycznie. Na potrzeby tego materiału możemy przyjąć, że dobre dyski talerzowe do NAS mają przepustowość zapisu i odczytu na poziomie 200MB/s. Zaznaczam, że wartość 200MB/s tyczy się albo odczyty albo zapisu. Jeżeli będziemy chcieli wykonywać te operacje równoległe osiągi również spadną znacząco.
Parametry storage – IOPS
Drugim z parametrów określających wydajność storage jest ilość losowych operacji wejścia/wyjścia na sekundę tzw IOPS. Najczęściej mamy z czymś takim do czynienia przy wielu operacjach na małych plikach na przykład przy operacjach na bazach danych. Pomiar powinno się robić albo przenosząc dane między różnymi systemami, żeby uniknąć kanibalizacji zasobów i zakłócenia przez to pomiaru. Można też użyć wirtualnych urządzeń, jak na przykład wysyłanie odczytanych danych do /dev/null dla testów odczytu, wtedy wszystkie dane wysyłane są „na Berdyczów” bez przejmowania się wydajnością urządzenia docelowego. W wypadku testów zapisu czytanie z /dev/zero sprawia, że danymi źródłowymi są po prostu zera.
Parametry storage – latency
Trzecim ważnym parametrem o którym muśmy pamiętać przy określaniu wydajności storage jest czas odpowiedzi dysku na żądanie tzw. Letency. Odgrywa większą rolę w wypadku obciążenia charakteryzującego się dużą ilością IOPS. Ten parametr w praktyce zależy od rodzaju dysków. Dla dysków talerzowych to koło 15 ms a dla dysków SSD to koło 2 ms. Na ten parametr nie jesteśmy w stanie wpłynąć konfiguracją poola więc chciałem tylko o nim powiedzieć.
Parametry storage – efektywna pojemność
Musimy też wspomnieć, że takie zalety jak redundancja, czy zwiększenie wydajności będą odbywały się najczęściej kosztem zmniejszenia efektywnej pojemności dysków. Czyli stosunek pojemności możliwej do wykorzystania do całkowitej sumy zainstalowanych dysków.
ZFS pool – Key study

Dla przykładu rozważmy sobie hipotetyczny storage składający się z dwunastu talerzowych dysków. Każdy dysk
ZFS pool – Stripe vDev
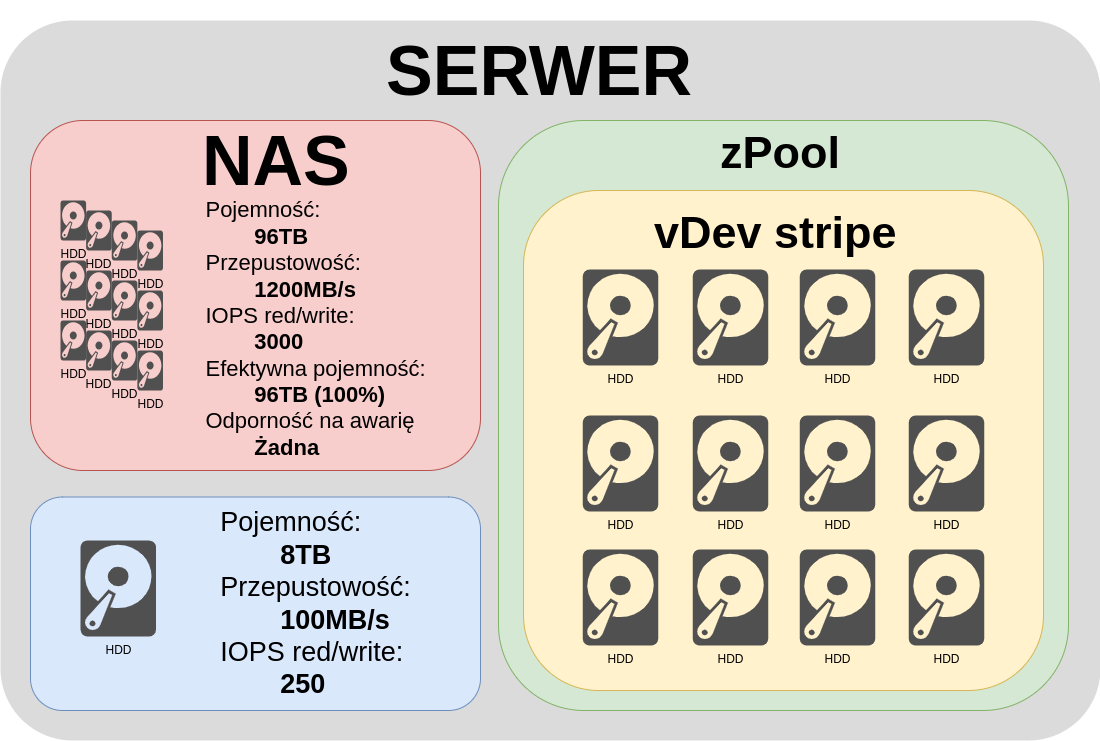
Zaczyniajmy od najprostszego przykładu w którym wszystkie dyski połączymy w jeden vDev stripes. W tym wypadku dane są równo dystrybuowane po wszystkich dyskach. Jak widzimy zarówno pojemność jak przepustowość i IOPS, po prostu mnożone razy ilość dysków. Sytuacja idealna z perspektywy wydajności, lepiej nie będzie. Dosyć jednak szybko widać gdzie jest kłopot. Awaria któregokolwiek z dysku sprawia, że tracimy wszystkie dane, sytuacja niedopuszczalna.
ZFS pool – Mirror Dev

Skrajnie odmiennym przypadkiem będzie jeżeli złączymy wszystkie dyski w jeden vDev mirror. Wówczas na każdym z dysków będziemy mieli zapisane te same dane. Wynik? Absurdalna wręcz odporność na awarię jedenastu dysków. Zwróćcie jednak uwagę jakie rozbieżności tworzą się między odczytem a zapisem zarówno przepustowość jak i IOPS. Skoro na wszystkich dyskach są takie same dane to odczyt może być zbalansowany między dyskami. Zapis już nie, bo na wszystkie dyski musimy zapisać dokładnie to samo. Oczywiście oba te przykłady były skrajnościami raczej nie przydatnymi w praktyce ale chciałem w skrócie pokazać dwa krańce możliwych rozwiązań. Czas przejść do czegoś bardziej praktycznego.
ZFS Pool – 6x vDev mirror
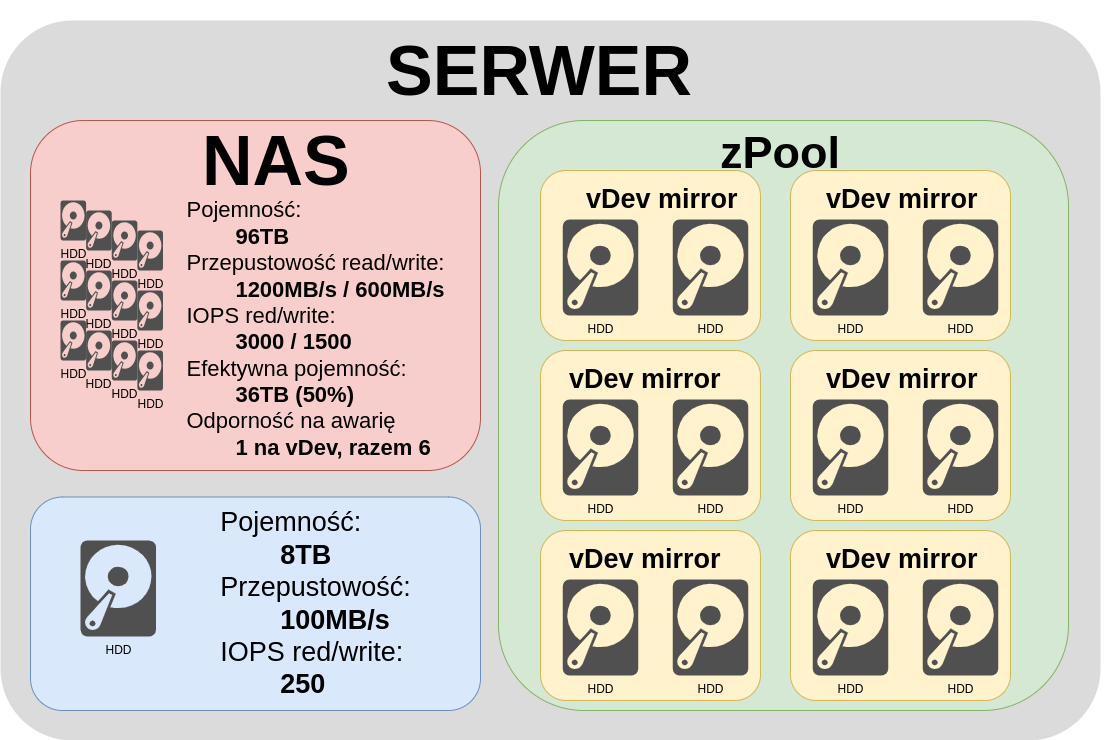
Przemontujmy nasz pool tym razem jako sześć vDev. Każdy vDev po dwa dyski w mirror. W takim wypadku sumaryczna przepustowość odczytu jest nadal iloczynem ilości odczytu pojedynczego dysku i ilości dysków. Mamy 1200MB/s Jest dobrze. Zwróćcie uwagę co się dzieje z zapisem. Strumień zapisu już nie dzielony na dwanaście urządzeń tylko na sześć po dwa urządzenia co daje nam 600MB/s. To samo IOPS, odczyt nadal możliwy z wszystkich dysków równolegle co daje 3000 IOPS no i zapis już nie na dwanaście urządzeń ale na sześć par po dwa urządzenia więc mamy 1500 IOPS. Odporność na awarie po jednym dysku w każdym vDev. Już jest bardziej sensownie, duża szybkość, spora odporność ale efektywna pojemność no cóż .. 50%. To już realny przykład wykorzystywany najczęściej jeśli potrzebujemy możliwie dużych osiągów na przykład przy obróbce wielu równoległych strumieni video na przykład w studiach nagraniowych.
RAIDz – efektywna pojemność
Przejdźmy już do kwintesencji ZFS czyli RAID-Z. Mamy trzy poziomy RAID Z1, Z2 i Z3. Numer odpowiada ilość dysków z sumami kontrolnymi, to forma nadmiarowości. Czyli RAID Z1 jest odporny na awarię jednego dysku Z2 dwóch i oczywiście Z3 trzech. Pojemność efektywną jest równa ilości dysków minus dyski z sumami kontrolnymi. To znaczy w rzeczywistości nieznacznie mniej ale na potrzeby chwili uprośćmy, że tak właśnie jest. Obliczanie osiągów RAIDZ może być sporą pułapką więc zanim przejdziemy do kalkulacji osiągów RAIDZ musimy sobie trochę powiedzieć jak działa ZFS a w szczególności RAIDZ.
RAIDZ – IOPS
Jeśli ZFS ma zapisać strumień danych na jakiś pool to dzieli go na bloki danych. Te bloki danych rozdziela równo między wszystkie swoje vDev. Te bloki danych są rozdzielane na mniejsze części danych zwane sektorami. Do tych sektorów dodawane są sektory z wyliczonymi sumami kontrolnymi i wszystkie te sektory są rozdzielane po dyskach w danym vDev. Tutaj ważna uwaga, ZFS działa na blokach danych. Do puki nie zostanie przetworzony jeden blok danych, czy to zapisany czy odczytany, nie zacznie się przetwarzanie następnego bloku. Wszystkie dyski w danym vDev będą w jednaj chwili wykonywać tylko jedną operację. Wynik tego jest taki, że z punktu widzenie ilości operacji IOPS cały vDev będzie działał z prędkością jednego dysku i to najwolniejszego. Zatrzymajmy się na chwilkę bo to ważne w zrozumieniu wydajności RAIDZ. Nie ma znaczenia ile dysków ma vDev czy trzy czy dwanaście to jego wydajność z perspektywy IOPS będzie równa wydajności jednego dysku. Jeżeli dołożymy do naszego pool drugi taki sam vDev to wydajność z punktu widzenia IOPS się podwoi, jak dodamy trzeci to będzie trzykrotna w poróżnianiu do pojedynczego vDev. I tak dalej. Wniosek z tego tak, że szukając wydajności pod kontem IOPS powinniśmy planować nasz pool tak, żeby miał raczej więcej i mniejszych vDev niż jeden duży.
RAIDZ – przepustowość
Tak oto gładko przechodzimy to przepustowości naszego RAIDZ. Tutaj sytuacja jest bardziej oczywista. Im więcej dysków uczestniczy w zapisie czy odczycie tym sumaryczny zapis czy odczyt jest większy. Należy tutaj odjąć dyski pełniące funkcję parzystości. Czyli jeden dysk dla Z1 dwa dla Z2 i trzy dla Z3.
RAIDZ – obliczenia parametrów

Chcąc stworzyć uogólniony wzór do obliczania parametrów vdev doszli byśmy do tego, że ilość IOPS całego vdev jest równa ilości IOPS poszczególnego dysku. Zarówno dla odczytu i dla zapisu. Jeżeli jednak chodzi o wydajność całego pool to po pierwsze IOPS poszczególnych vDev się sumują im więcej vDev tym więcej IOPS. Po drugie o czym też warto pamiętać to, że dane w pool są rozdzielane równo między wszystkimi vDev w pool i dopóki wszystkie vDev nie skończą przetwarzać danych następna porcja danych nie zostanie rozdzielona. Wniosek z tego taki, że jeżeli jeden z naszych vDev z jakiegoś powodu będzie miał dużo mniej IOPS to inne vDev zrównają w dół z prędkością do najwolniejszego. Przechodząc do porównania, najpierw pamiętajcie proszę, że przedstawione w tabeli wyliczenia są pogladowe i mają dawać bardziej pojęcie o mechanizmach niż dokładnie wyniki. Tabela przedstawia różne konfigurację połączenia dwunastu identycznych dysków. Przedstawiany na podstawie hipotetycznego dysku o pojemności 8TB, 250 IOPS i przepustowość 100MB/s zarwano odczytu i zapisu.
Podsumowanie
Słowem podsumowania tej opowieści o leyout ZFS pod kontem wydajności chciałem powiedzieć, że mam nadzieję, że udało mi się rozjaśnić sposób planowania pool i przekonać jak duże może to mieć znaczenie zwłaszcza w wypadku wielodyskowych storage.
Ważne jest, żeby zanim się zacznie dobrze przeanalizować co będziemy trzymać na naszym storage zanim zadecydujemy się na konkretną konfigurację swojego pool. Potem każdy już we własnym zakresie na bazie jego indywidualnych potrzeb będzie w stanie zadecydować jaki layout będzie dla niego odpowiedni lub porostu zorientuje się, gdzie popełnił błąd.